Puzzle Pong II - Least Nonconstructable Positive Integer
Table of Contents
| Github | https://gist.github.com/ambuc/731f2d9b789a5e4e32bdafbd60bf7ff8 |
|---|
The Puzzle⌗
Josh Mermelstein and I have decided to begin challenging each other to a series of a math/programming puzzles. Here was his most recent puzzle:
Given a) the list of numbers $[1, 2, 3, 4, 5]$, b) unlimited parentheses, and c) the operations $+$, $-$, $\times$, $/$, $\wedge$, and $!$, it is possible to construct many integers. For example,
- $1 = 1 + 2 - 3 - 4 + 5$, and
- $2 = 1 + (((2 + 3) * 4!) / 5!)$, etc.
What is the least positive integer that cannot be written this way?
- Numbers must appear in order, each exactly once.
- You may not take the factorial of a factorial (i.e. $(3!)! = 720$).
- Concatination is forbidden (i.e. $1 + 23 + 4 + 5$).
- Unary negative is forbidden (i.e. $13 = (-1) + 2 + 3 + 4 + 5$)
Let’s define this function a little more. I’d like to call the output the least nonconstructable positive integer, or $\text{LNPI}$ of an ordered list. In this case, the ordered list is $[1,2,3,4,5]$.
OK, how do we start?
Abstract Syntax Trees⌗
Let’s represent an expression like $(1!+2)-3$ as an abstract syntax tree; terminal nodes are integers, and all the other nodes are operators.
$$(1! + 2) - 3$$
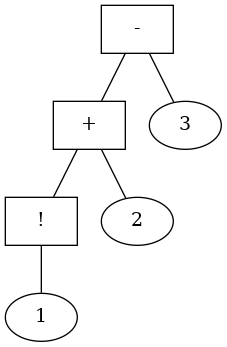
It makes sense to have two types of operators; functions of one argument, like the factorial, and combining functions of two arguments, like all the rest.
Haskell makes it easy to create abstract data types and start playing with them.
AST Implementation⌗
We can represent our values Val as unrounded ratios of long ints, or Integers. This means we never lose precision to rounding / near-zero numbers.
type Val = Ratio Integer
As we discovered before, there are two things we can do to Vals:
- take a function of one of them: $y = f(x)$
- perform an operation on two of them: $y = f(x_1, x_2)$.
data Fn = Id | Fact deriving (Bounded, Enum)
data Op = Plus | Sub | Mult | Div | Exp deriving (Bounded, Enum)
Here Id is the identity function $y(x) = x$. The rest should be self-explanatory.
Finally we need an expression type Expr, which can be either:
- a raw
Val:V (Ratio Integer), - an expression
E1of 1 argument, which takes a functionFnand an expression to operate on, or - an expression
E2of 2 arguments, which takes an operationOpand a tuple of two expressions to operate on.
data Expr = V Val | E1 Fn Expr | E2 Op (Expr,Expr)
Let’s even derive custom Show instances so we can pretty-print them, for debugging purposes.
instance Show Op where
show Plus = "+"
show Sub = "-"
show Mult = "*"
show Div = "/"
show Exp = "^"
instance Show Expr where
show (V a) = show $ round a
show (E1 Id e) = show e
show (E1 Fact e) = show e ++ "!"
show (E2 o (e1,e2)) = "(" ++ show e1 ++ show o ++ show e2 ++ ")"
If we play with this in a ghci shell, we see:
> E2 Sub ( E2 Plus ( E1 Fact ( V 1 ), V 2 ), V 3 )
((1!+2)-3)
This is good. Let’s figure out how to evaluate these expressions.
Evaluation⌗
The type signature of eval should be eval :: Expr -> Maybe Val, since not all expressions return values. (Imagine taking the factorial of a non-integer, or dividing by zero). To accomplish this in an elegant way we make use of monad stuff like =<<, <$>, and <*>, which is worth exploring in some detail in a moment.
eval :: Expr -> Maybe Val
eval (V a) = Just a
eval (E1 f e) = calc1 f =<< eval e
eval (E2 o (e1, e2)) = calc2 o =<< (,) <$> eval e1 <*> eval e2
calc1 :: Fn -> Val -> Maybe Val
calc1 Id a = Just a
calc1 Fact a = guard (isInt a && a<100 && a>0) >> Just f
where f = facts !! (pred . fromIntegral . numerator) a
calc2 :: Op -> (Val, Val) -> Maybe Val
calc2 Plus (a,b) = Just $ a + b
calc2 Sub (a,b) = Just $ a - b
calc2 Mult (a,b) = Just $ a * b
calc2 Div (a,b) = guard (b/=0) >> Just (a/b)
calc2 Exp (a,b) = makeExp
where makeExp
| a == 0 = Just 0
| a == 1 = Just 1
| not (isInt b) = Nothing
| abs b > 1023 = Nothing
| otherwise = Just $ a ^^ numerator b
Obviously not all computation is valid. We refuse to:
- take the factorial of any negative number,
- take the factorial of any non-integer, or
- divide by zero.
One hurdle of this problem was the discovery that it is possible to quickly generate numbers too large for the computer to handle: for example,
$$\texttt{1+(2^(3^(4^5)))} = 1 + 2^{3^{4^5}} \approx 10^{10^{488}}$$
So we end up doing a fair bit of bounds checking. We also refuse to:
- compute the factorial of any integer greater than a hundred,
- take an exponent to the power of any non-integer,
- take an exponent to the power of any number outside $[-1023..1023]$,
Additionally, we also precompute the factorial of all numbers for which the factorial is allowed, $[0..100]$, and store them in facts; thus calc1 Fact a is just a lookup with guards.
Finally, we avoid some computation by noticing that $a^1 = a$ and $0^b = 0$.
OK, let’s try evaluating the above expression!
input output
> eval $ E2 Sub (E2 Plus (E1 Fact (V 1), V 2), V 3) Just (0 % 1)
> eval $ E2 Sub (E2 Plus (E1 Fact (V 1), V 2), V 4) Just ((-1) % 1)
> eval $ E2 Div (V 1, V 0) Nothing
Perfect: when an expression is valid, we compute the Val as a Just (Ratio Integer); when an expression is invalid, we return Nothing.
Maybes and Monads⌗
Let’s take a moment and explore some of the above Haskell in detail. I’m going to try and explain how I accidentally invented the Monad while trying to solve a subproblem, as was predicted in You Could Have Invented Monads! (And Maybe You Already Have.), a wonderful article about this exact phenomenon.
Imagine a function like calc1 :: Fn -> ? -> ?. How should we write this?
First Try⌗
Writing it like calc1 :: Fn -> Maybe Val -> Maybe Val essentially requires us to write two cases:
calc1 :: Fn -> Maybe Val -> Maybe Val
calc1 _ Nothing = Nothing
calc1 Id (Just a) = Just a
calc1 Fact (Just a) = if (canFactorial a) then Just (factorial a) else Nothing
I’m not sure that will carry over well to calc2:
calc2 :: Fn -> (Maybe Val, Maybe Val) -> Maybe Val
calc2 _ (Nothing, _ ) = Nothing
calc2 _ (_, Nothing) = Nothing
calc2 Plus (Just a, Just b ) = Just $ a + b
calc2 Minus ...
This is OK, but let’s find a better way – maybe by assuming we won’t pass invalid expressions in the first place.
Second Try⌗
Writing it like calc1 :: Fn -> Val -> Maybe Val assumes a valid expression, so we can write:
calc1 :: Fn -> Val -> Maybe Val
calc1 Id a = Just a
calc1 Fact a = if (canFactorial a) then Just (factorial a) else Nothing
calc2 :: Fn -> (Val, Val) -> Maybe Val
calc2 Plus (a,b) = Just $ a + b
calc2 Minus ...
This is much better. So if our type signatures look like
calc1 :: Fn -> Val -> Maybe Val
calc2 :: Fn -> (Val, Val) -> Maybe Val
then what does eval look like? It would need to do something like
eval :: Expr -> Maybe Val
eval (V a) = Just a
eval (E1 f e) = calc1 f (???)
And here’s where our trouble begins. Remember that we want to evaluate e before passing it into calc1. So we’d have to check if it was valid first.
eval (E1 f e) = if (isJust $ eval e)
then (calc1 f (fromJust $ eval e))
else Nothing
This is nuts. Luckily this type of implicit Maybe checking is easy, since the
Maybe type is a
monad,
and implements the Monad, Functor, and Applicative types.
Functors, really quick⌗
Quick functor recap:
maplets us apply a function over a list:map fn [x,y] = [fn x, fn y]fmaplets us apply a function inside a container type:fmap f (m a) = m (f a).
Note also that <$> is an infix synonym for fmap. Confused? See the following examples:
> map (+1) [1,2] [2,3]
> fmap (+1) (Just 1) Just 2
> (+1) <$> Just 1 Just 2
> (+1) <$> Nothing Nothing
One benefit of fmapping over the Maybe monad is that if we pass it Nothing, it doesn’t need to unwrap and apply; it’ll just pass Nothing through unscathed.
fmap, really quick⌗
So remember the above problem:
> calc1 Fact (4%1) Just (24%1)
> calc1 Fact Nothing <error>
OK, that’s expected. Let’s try using <$>
> calc1 Fact <$> Just (4%1) Just (Just (24%1))
> calc1 Fact <$> Nothing Nothing
So, good news and bad news. We can unwrap Just a and apply the function to the interior, but we pass it back re-wrapped, since that’s what <$> does. Sadly, that’s also what calc1 does. Here’s a clue:
> :type (<$>) (<$>) :: Functor f => (a -> b) -> f a -> f b
This makes sense: <$> expects a function like (a -> b) which doesn’t have an opinion on how to re-wrap b itself. So maybe <$> isn’t the function we want?
Monads, really quick⌗
At this point I searched Hoogle for (a -> f b) -> f a -> f b and got, of course… the Monad.
> :type (=<<) (=<<) :: Monad m => (a -> m b) -> m a -> m b
> :type (>>=) (>>=) :: Monad m => m a -> (a -> m b) -> m b
There’s lots more to the monad, but for now we can use it as a way to take a value in context, apply a context-aware function, and return some output in context.
> calc1 Fact =<< Just (4%1) Just (24%1)
> calc1 Fact =<< Nothing Nothing
What about calc2? It needs to take a tuple of Exprs, and neither of them can be Nothing. Turns out we can use the fmap infix <$> and their friend the sequential application infix <*>. Here’s a set of three trials:
(+) <$> Just 1 <*> Just 2 Just 3
(+) <$> Just 1 <*> Nothing Nothing
(+) <$> Nothing <*> Just 2 Nothing
So finally we can simply write calc2 o =<< (,) <$> eval e1 <*> eval e2. Thus,
eval :: Expr -> Maybe Val
eval (V a) = Just a
eval (E1 f e) = calc1 f =<< eval e
eval (E2 o (e1, e2)) = calc2 o =<< (,) <$> eval e1 <*> eval e2
Solving the Puzzle⌗
Technically this is all we need to start solving the puzzle. Now that we have a way to compose and evaluate expressions, we just need to generate and evaluate all of them.
Generating all expressions⌗
Let’s talk about partitioning a strictly ordered list.
One interesting aspect of this problem is that because our numbers have to be in order, the nodes containing the values (for example) $[1..3]$ will appear in order, from left to right, as the terminal nodes of our AST. This means that we can generate all possible ASTs by taking our root node and splitting the numbers $[1..3]$ at some point, throwing the lesser half on the left, and the greater half on the right.
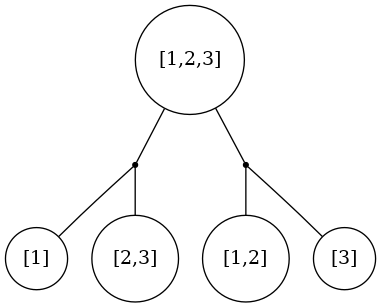
It’s easy to see how we can apply this recursively to generate all tree shapes. Then we can insert all possible iterations at each op node, and all possible functions at each function. There are only two functions, and one is Id which leaves the value untouched.
We implement the partition algorithm as:
mkPart :: [a] -> [([a],[a])]
mkPart xs = tail $ init $ zip (inits xs) (tails xs)
such that
> mkPartitions [1,2,3] [([1],[2,3]),([1,2],[3])]
valuesFrom in Theory⌗
This is excellent. Let’s write the function valuesFrom, which takes an ordered list and returns all possible values which can be generated from combining it as described above. Note:
valuesFrom 1will just be[1, 1!] = [1,1]valuesFrom 3will just be[3, 3!] = [3,6]
valuesFrom :: [Val] -> [Val]
valuesFrom [x] = mapMaybe eval [ E1 f (V x) | f <- functions ]
valuesFrom xs = mapMaybe eval [ E1 f $ E2 o (V va, V vb)
| f <- functions
, o <- operations
, (as, bs) <- mkPartitions xs
, va <- valuesFrom as
, vb <- valuesFrom bs
]
We use mapMaybe to map eval over a list and discard the Nothings (and fromJust the Just as). This is great! It doesn’t check for duplicates or anything, but it’s a good start.
Caching⌗
In practice, we would like to cache valuesFrom.
Here’s why: in calling valuesFrom [1,2,3,4,5], we end up evaluating valuesFrom [2,3,4] twice: once as part of [1,2,3,4] and once as part of [2,3,4,5]. See the above tree, which is an expansion of the earlier one for a larger ordered list.
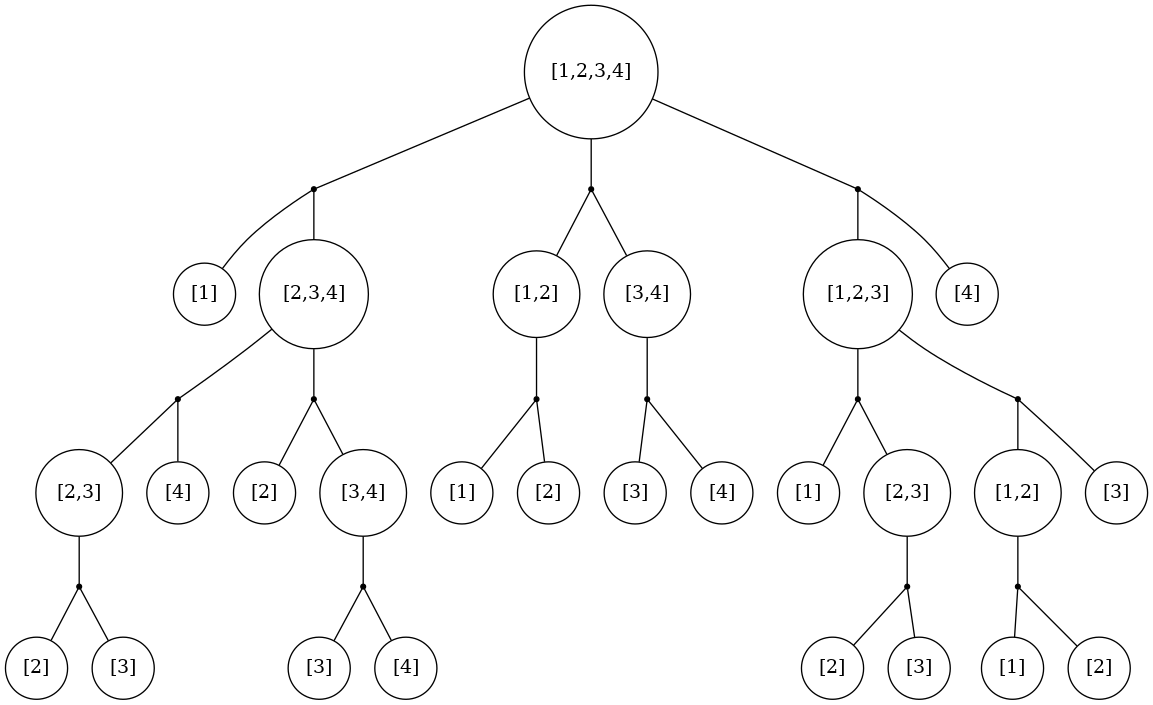
You can see we end up evaluating f([2,3]) twice, f([1,2]) twice, f([3,4]) twice, etc.
You can imagine how this inefficiency bares its teeth for higher-length ordered lists; evaluating f([1,2,3,4,5]) will evaluate [2,3] four times; as a part of [1,2,3],[1,2,3,4],[2,3,4], and [2,3,4,5].
So let’s generate a big Map. On that note, Map is Haskell’s version of a key/value pairing, what would be a dict in Python. Here’s what it will contain:
- the keys in this map should be consecutive sequences like
[1], [1,2], [2,3,4], [4,5], etc., and - the values should be sets of values
S.Set Valwhich can be created from combining those numbers in the key.
To generate this recursively from the bottom up, we can first generate a map of all keys of length 1, and then use it to quickly generate a map of all keys of length 2, and so on and so on and so on.
Let’s do it.
valuesFrom in Practice⌗
Here’s how it all looks together: valuesFrom range does a M.findWithDefault (S.empty) range on a map, which is the union of two smaller maps:
$$ \text{Map}([1..n]) = \text{Map}(n) \ \bigcup \ \text{Map}([1..(n-1)]) $$
where prevMap is the mkMap of a smaller subset, and thisMap is the set of the values of the expressions generated in exprsFrom, which uses valsFrom the partitioned right- and left-available values. Check it out:
valuesFrom :: [Val] -> S.Set Val
valuesFrom range = M.findWithDefault S.empty range
$ mkMap (length range)
where
mkMap :: Int -> M.Map [Val] (S.Set Val)
mkMap 0 = M.empty
mkMap n = M.union prevMap thisMap
where
prevMap = mkMap $ pred n
thisMap = foldr (\sq -> M.insert sq $ mkSet sq) M.empty $ subsequences n
mkSet = S.fromList . mapMaybe eval . exprsFrom prevMap
exprsFrom :: M.Map [Val] (S.Set Val) -> [Val] -> [Expr]
exprsFrom prevMap [x] = [ E1 f (V x) | f <- functions ]
exprsFrom prevMap xs = [ E1 f $ E2 o (V va, V vb)
| f <- functions
, o <- operations
, (as, bs) <- mkPartitions xs
, va <- valsFrom as
, vb <- valsFrom bs
]
where valsFrom xs = S.toList $ M.findWithDefault S.empty xs prevMap
subsequences n = filter ((== n) . length) $ map (take n) $ tails range
So, with caching, here’s what each valuesFrom function call ends up looking like:
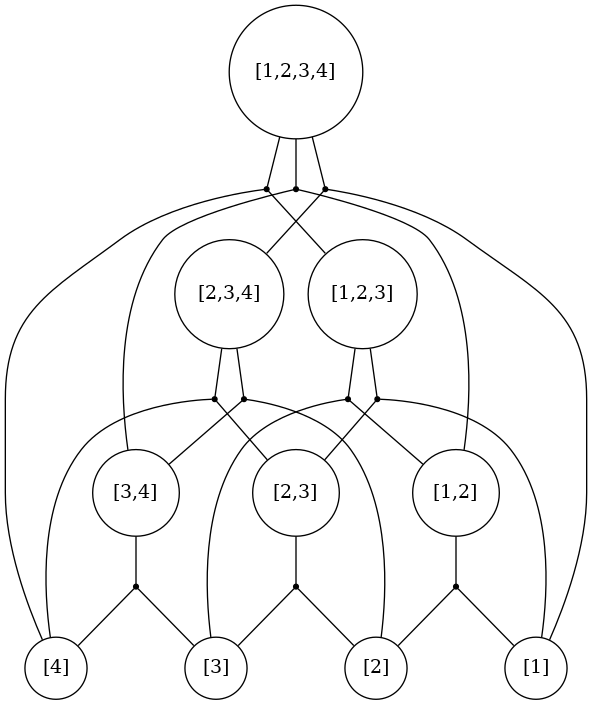
Putting it all together⌗
We’re so close to the end here.
We can get a set of all possible numbers from a range xs with valuesFrom xs. This returns a set we can filter for just positive integers; then we want to turn that into a list and find its first gap; where
-- > firstGap [1,2,3,5,6] = 4
firstGap :: (Num a, Eq a) => [a] -> a
firstGap ls = 1 + ls !! (head . findIndices (/=1) . gaps) ls
where gaps :: Num t => [t] -> [t]
gaps [x] = []
gaps (x:xs) = (head xs - x) : gaps xs
Finally, we can define
lnpi :: [Val] -> Integer
lnpi = numerator . firstGap
. S.toList . S.filter (>0)
. S.filter isInt. valuesFrom
So, let’s try it!
> lnpi [1..5] 159
and that’s our final answer; 159 is the smallest integer we can’t construct from the numbers $[1..5]$.
For the complete code, please see this gist.
Runtime⌗
Finally, the runtime…
j@mes $ ghc -O2 lnpi.hs && time ./lnpi
[1 of 1] Compiling Main ( lnpi.hs, lnpi.o )
Linking lnpi ...
159
real 0m0.332s
user 0m0.327s
sys 0m0.003s
This is phenomenal. Early drafts of this took anywhere from one to ten minutes. The secret to this low runtime is evaluating the values early for re-use in other expressions, and nubbing down lists to sets as early as possible, for fewer iterations.
The Puzzles⌗
So Josh actually posed me a set of puzzles. Once we discussed how the performance was and how easy it was to play around with different ideas in this space, we settled on a set of bonus problems; provided here are their questions, answers, runtimes, and some comments on performance.
Puzzle One⌗
Find the least nonconstructable integer from the ordered list [1,2,3,4,5]:
This was the original problem. The solution 01.hs was trivial:
$ ghc -O2 operationsLibrary.hs 01.hs && time ./01
159
0m0.333s
Puzzle Two⌗
Find the least nonconstructable integer from any length five, strictly
increasing sublist of [0..9]:
main = print $ first (map numerator)
$ minimumBy (compare `on` snd) $ map (id &&& lnpi) $ sets [0..9] 5
$ ghc -O2 operationsLibrary.hs 02.hs && time ./02
([0,2,6,8,9],2)
0m39.127s
So I actually played a lot with trying to parallelize this one. A first attempt to compute one large cached map of all sublists of [0..9] took a very large amount of time, and was too large to fit entirely in memory; the process of swapping bits of it in and out was expensive. It turned out to be faster to compute lnpi([]) from scratch each time, at anywhere from 0.03s to 3s each, depending on how many possible products were exponentially large and could be dropped immediately.
I did play with the Control.Parallel library for a bit, and ended up using pseq and par to parallelize this independent computation of lnpi([]) across four cores, for a slightly better runtime:
main = print
$ first (map numerator)
$ a `par` b `par` c `par` d `pseq` reduceFunc [a,b,c,d]
where [a,b,c,d] = map (reduceFunc . map mapFunc)
$ segmentInto (sets [0..9] 5) 4
reduceFunc = minimumBy (compare `on` snd)
mapFunc = id &&& lnpi
segmentInto xs n = map (\x -> take y $ drop (y*x) xs) [0..pred n]
where y = succ $ div (length xs) n
$ ghc -j -O2 -threaded -rtsopts operationsLibrary.hs 02b.hs --make -fforce-recomp && time ./02b +RTS -N4
([0,2,6,8,9],2)
0m23.407s
Puzzle Three (a,b)⌗
What lists can’t make one?
Here we end up using valuesFrom directly; we don’t care about the lnpi at all. We can use map (f &&& g) which takes an input x and returns a tuple (f x, g x). We use list function elem to see that 1 isn’t a possible value, and print the (empty) list.
main = print
$ filter (not.snd)
$ map ( id &&& elem 1 . valuesFrom ) $ sets [0..9] 5
$ ghc -O2 operationsLibrary.hs 03.hs && time ./03
[]
0m36.4s
This performance was a little lacking, but we can reoptimize by fetching the list of expressionsFrom and evaluating one-by-one to see if they are Just (1%1); we skip the process of mapping ids and the cost of holding all the values in memory instead of printing an empty list lazily.
main = print
$ map (map numerator)
$ filter (isNothing . find1)
$ sets [0..9] 5
where find1 xs = if null ls then Nothing else Just (head ls)
where ls = filter (\e -> eval e == Just (1%1)) $ expressionsFrom xs
$ ghc -O2 operationsLibrary.hs 03b.hs && time ./03b
[]
0m7.087s
What’s expressionsFrom?⌗
It’s a lot like valuesFrom, except we don’t evaluate the expressions at every possible step. To write both valuesFrom and expressionsFrom I was able to extract a lot of shared abstractions. Here is the code for them both, all in one place. This looks different from the form of valuesFrom above, but it has the same performance and interface.
makeMap :: Ord a => [a] -> ((M.Map [a] b, [a]) -> b) -> M.Map [a] b
makeMap range insertFn = mkMap (length range)
where mkMap 0 = M.empty
mkMap n = M.union prev this
where prev = mkMap (n-1)
this = foldr f z ls
where f sq = M.insert sq $ insertFn (prev, sq)
z = M.empty
ls = filter ((==n).length) $ map (take n) $ tails range
valuesFrom :: [Val] -> [Val]
valuesFrom range = S.toList $ M.findWithDefault S.empty range $ makeMap range insFn
where insFn = S.fromList . mapMaybe eval . exprsFrom
exprsFrom :: (M.Map [Val] (S.Set Val), [Val]) -> [Expr]
exprsFrom (prevMap, [x] ) = [ E1 f (V x) | f <- functions ]
exprsFrom (prevMap, range) = [ E1 f $ E2 o (V va, V vb)
| f <- functions
, o <- operations
, (as, bs) <- mkPart range
, va <- valsFrom as
, vb <- valsFrom bs
]
where valsFrom range = S.toList $ M.findWithDefault S.empty range prevMap
expressionsFrom :: [Val] -> [Expr]
expressionsFrom range = M.findWithDefault [] range $ makeMap range exprsFrom
where exprsFrom :: (M.Map [Val] [Expr], [Val]) -> [Expr]
exprsFrom (prevMap, [x] ) = [ E1 f (V x) | f <- functions ]
exprsFrom (prevMap, range) = [ E1 f $ E2 o (ea, eb)
| f <- functions
, o <- operations
, (as, bs) <- mkPart range
, ea <- exprsFrom (prevMap, as)
, eb <- exprsFrom (prevMap, bs)
]
Puzzle Three (c)⌗
Print how each list can make one.
By using expressionsFrom we can find the first expression that evaluates to $1$, and avoid evaluating the entire possible tree.
main = mapM_ print $ map (map numerator &&& find1) $ sets [0..9] 5
where find1 xs = if null ls then Nothing else Just (head ls)
where ls = filter (\e -> eval e == Just (1%1)) $ expressionsFrom xs
$ ghc -O2 operationsLibrary.hs 03c.hs && time ./03c
([0,1,2,3,4],Just (0+(1+((2-3!)+4))))
([0,1,2,3,5],Just (0+(1+(2+(3-5)))))
([0,1,2,4,5],Just (0+((1*2)+(4-5))))
([0,1,3,4,5],Just (0+(((1+3)!/4)-5)))
([0,2,3,4,5],Just (0+(2+((3-4)^5))))
([1,2,3,4,5],Just (1+((2-(3+4))+5)))
([0,1,2,3,6],Just (0+(1+((2*3)-6))))
([0,1,2,4,6],Just (0+(1+(2+(4-6)))))
([0,1,3,4,6],Just (0+((1*3)+(4-6))))
([0,2,3,4,6],Just (0+(2+(3-(4!/6)))))
...
0m7.085s
Return Volley⌗
Josh, here is my puzzle:
I saw a Sol Lewitt exhibition at a museum a few years ago which consisted of a series of variations of incomplete cubes. There were 122 of them, and each was a contiguous subset of lines which traced the twelve edges of the skeleton of a cube. The trick was that these subsets were unique across rotation but not reflection.
{kind=link}
Create a script / renderer to generate the table of Varations of Incomplete Open Cubes, and then apply it to the skeleton of each platonic solid.
{kind=link}
Some light reading: Analysis of Variations of Incomplete Open Cubes by Sol Lewitt, a paper by Michael Allan Reb (2011).